
我们打开开发者工具看一眼百度搜索结果的链接设置:
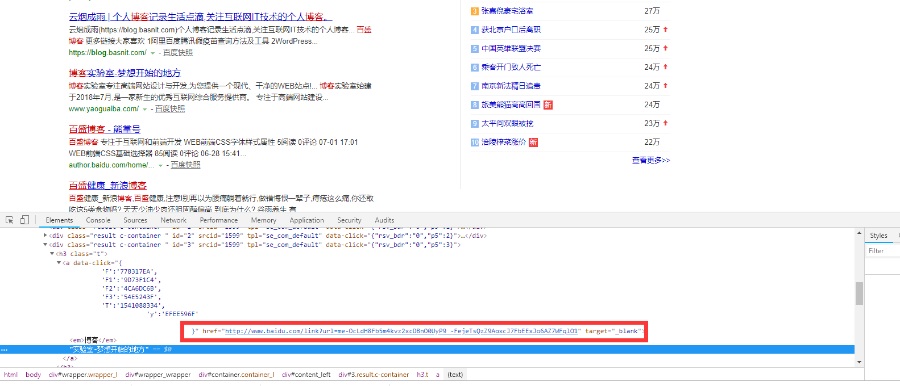
从上面的截图,我们可以看出搜索结果页的链接并不是直接指向待访问网站,而是一个百度自己的网址我们姑且称之为百度中转页,后面再通过location活着其他方式跳转到了待访问网站的网站,所以排除掉结果站加载速度的问题,百度中转页速度也会影响我们从百度结果页跳转到待访问网址的速度,对于待访问的网站,其访问速度我们是没办法优化的,但是我们可以想办法去掉百度中转这步,直接跳转到待访问网站,来加快我们获取资源的速度。
现在的问题就是如何获取待访问的网址,在上面的截图中我们已经发现百度中转的时候对于待访问的网站是通过url参数标示的,而url参数是一个加密的结果,目前网上也没有对于这部分加密算法的研究,通过进一步抓包百度中转页的跳转我们可以发现,百度中转页是通过location来跳转到待访问网站的,而location里面就是明文的待访问网址,但是通过js我们是没办法直接获取响应中的location参数的,现在我们有两种方式可以解决:
1、通过后端语言解析出response头信息中的location参数,然后前端将百度中转页地址传给后端做解析,得到解析结果,解析代码相对简单,这里不做演示。
2、在之前的基础知识中我们了解到插件是可以拦截并修改一些请求参数的,那我们可以充分利用这点来解析location参数,前面我们有说js不能直接解析location参数,为什么呢?xhr对象是存在getResponseHeader方法的,原因是location会导致页面重定向,js是没办法阻止掉这次重定向的,所以请求的是最终的待访问地址,getResponseHeader获取到的也是待访问地址的响应头,这并不是我们想要的,而且由于待访问地址可能是http的也可能是https的,而百度搜索页是https的,还可能出现mixcontent的问题,这个是允许跨域没办法解决的。但是利用插件我们可以移除掉响应头中的location参数,从而变相的阻止掉了本次跳转并且规避了mixcontent的问题,因为我们从始至终请求的都是百度的地址,talk is cheap,show me the code,多说无益嘛,下面是关键代码:
var modifyFieldName = 'location';
var searchUrlReg = /https:\/\/www\.baidu\.com\/link\?url=/;
chrome.webRequest.onBeforeSendHeaders.addListener(function(details){
var url = details.url;
if (searchUrlReg.test(url)) {
details.requestHeaders.push({
name: 'Access-Control-Expose-Headers',
value: 'Redirect'
});
}
return {requestHeaders: details.requestHeaders};
},
{
urls : [""]
},
["blocking", "requestHeaders"]);
chrome.webRequest.onHeadersReceived.addListener(function(details) {
var url = details.url;
var responseHeaders = details.responseHeaders;
var allowOriginHeader = responseHeaders.find(function(rh, index){
if (rh.name === modifyFieldName) {
responseHeaders[index]['value'] = 'https://www.baidu.com/';
return true;
}
if (rh.name.toLowerCase() === modifyFieldName.toLowerCase() && searchUrlReg.test(url)) {
responseHeaders.push({
name: 'redirect',
value: rh.value
});
responseHeaders.splice(index, 1);
}
});
return {
responseHeaders: responseHeaders
};
},
{
urls : [""]
},
["responseHeaders","blocking"]);
在上面的代码中我们拦截了响应头,并删除了location字段,同时将location字段的值赋值给了redirect字段,并作为一个自定义字段返回,但是这里有一点需要注意的是自定义的redirect并不能直接通过xhr的getResponseHeader方法获得,需要在Access-Control-Expose-Headers字段中添加redirect字段才能暴露出去,因为redirect非一个标准的头信息字段。
在阻止掉了跳转,并添加了自定义字段之后,我们就可以通过js获取了,下面是js获取redirect字段的代码:
function getRealLink(url, callback) {
var xmlhttp = new XMLHttpRequest();
xmlhttp.open('GET', url, true);
xmlhttp.onload = function() {
var redirect = this.getResponseHeader('redirect');
if (redirect) {
callback(redirect);
}
}
xmlhttp.send();
}
核心部分弄懂了,剩下的工作我们就是需要将百度搜索结果页的中转地址替换为最终的待访问地址了,下面是代码:
(function() {
let timer = null;
const container = document.querySelector('#wrapper_wrapper');
replaceUrl();
watchUpdate();
function replaceUrl() {
unWatchUpdate();
const resultLink = [].slice.call(document.querySelectorAll('.result h3 a, .result-op h3 a'), 0);
resultLink.forEach(function(item) {
var url = item.getAttribute('href').replace(/&wd.*$/, '');
if (/https?\:\/\/www\.baidu\.com\/link\?url/.test(url)) {
getRealLink(url.replace('http', 'https'), function(sc) {
item.href = sc;
});
}
});
watchUpdate();
}
function getRealLink(url, callback) {
var xmlhttp = new XMLHttpRequest();
xmlhttp.open('GET', url, true);
xmlhttp.onload = function() {
var redirect = this.getResponseHeader('redirect');
if (redirect) {
callback(redirect);
}
}
xmlhttp.send();
}
function watchUpdate() {
container.addEventListener('DOMSubtreeModified', function() {
handleUpdate();
}, false);
}
function unWatchUpdate() {
container.removeEventListener('DOMSubtreeModified', handleUpdate);
}
function handleUpdate() {
timer && clearTimeout(timer);
timer = setTimeout(function() {
replaceUrl();
});
}
}());
因为百度搜索还可能是异步的,所以我们这里还使用了DOMSubtreeModified来监听异步的更新。
剩下的google搜索结果页链接直链的这里就不做分析了,相比比百度简单太多,中转页的url参数就是明文的待访问地址,我们只需要提取出待访问地址,然后做替换就是了,异步搜索的处理和百度的是一样的。
最后附上插件源码:点击这里获取。